Consideremos \(\hat{y}\), un predictor de \(y\) que es función de \(X\)
Definamos el error de la predicción como \[L(e)=L(y-\hat{y})\]
\(L(e)\) es la función de pérdida asociada al error \(e\)
Si \(y\) y \(\hat{y}\) son aleatorios, se busca minimizar la pérdida esperada \(E(L(e))\)
Si la función depende del vector \(X\) de dimensión \(k\), la pérdida esperada se puede escribir como \(L(e)=L(y-\hat{y}|X)\)
La función de pérdida típicamente usada es la del error cuadrático: \[min_{\hat{y}} E((y-\hat{y})^2)\]
Funciones de pérdida
En el caso general, no hacemos supuestos sobre la forma de la expectativa y la podemos estimar de forma no paramétrica
Comúnmente, se especifica una función \(E(y|X)=g(X,\beta)\)
El problema es escoger \(\beta\) que minimice la pérdida dentro de la muestra: \[\sum_{i=1}^{N}L(e_i)=\sum_{i=1}^{N}e_i^2=\sum_{i=1}^{N}(y_i-g(x_i,\beta))^2\]
Una forma particular es asumir que \(g(\cdot)\) es lineal en \(\beta\), es decir, \(E(y|X)=X\beta\)
Regresión lineal múltiple
Definiciones
\(N\) observaciones
\(y_i\) variable dependiente, escalar
\(x_i\) vector de \(k\) regresores, incluyendo el incercepto
\[x_i=\left(\begin{matrix} x_{i1} \\ x_{i2} \\ \vdots \\ x_{ik} \end{matrix}\right)\] El modelo lineal para la observación \(i\) es
\(\hat{\beta}_{MCO}\) puede ser calculado si \(X'X\) es no singular
Una matriz \(A\) es singular si tiene determinante cero
Una matriz singular no es invertible
El problema cuando hay multicolinealidad es que \(X'X\) no puede ser invertida y, por tanto, \(\hat{\beta}_{MCO}\) no puede ser calculado
Revisión de teoría asintótica
Teoría asintótica
Basado en Cameron y Trivedi (2005) (CT), Apéndice A, secciones A1 - A6
Consideremos secuencias de variables aleatorias \(b_N\)
Queremos decir algo sobre \(b_N\) cuando \(N\to \infty\):
La convergencia en probabilidad de \(b_N\) a un límite \(b\) (una constante)
Si el límite \(b\) es en sí misma una variable aletoria, queremos conocer su distribución límite
En econometría pensamos las secuencias en términos de estimadores, que son regularmente funciones de sumas y promedios
Esto nos permite usar leyes de los grandes números y teoremas de límite central para derivar resultados sobre las características de estos estimadores
Convergencia de secuencias
\(\{a_N\}\) converge a \(a\) si para todo \(\varepsilon>0\) existe \(N^*=N(\varepsilon)\) tal que para \(N>N^*\), \(|a_N-a|<\varepsilon\)
Por ejemplo:
\[a_N=2+3/N\]
Converge a \(a=2\) pues \(|a_N-a|=3/N<\varepsilon \quad \forall \quad N>N^*=3/\varepsilon\)
Convergencia en probabilidad
Cuando tenemos una secuencia de variables aleatorias, no podemos estar seguros de que la diferencia estará siempre dentro del límite \(\varepsilon\)
Buscamos entonces que la probabilidad de estar en el límite de \(\varepsilon\) sea muy arbitrariamente cercana a uno
Una variable aleatoria \(\{b_N\}\)converge en probabilidad a \(b\) si para todo \(\varepsilon\) y \(\delta>0\) existe \(N^*=N*(\varepsilon, \delta)\) tal que:
\[Pr(|b_n-b|<\varepsilon) > 1-\delta\] La notación más usada es escribir \(p\lim b_n=b\) o \(b_n\xrightarrow{p}b\), donde \(b\) puede ser una constante o una variable aleatoria
Consistencia de estimadores
Sea \(\{b_N\}\) una secuencia de parámetros estimados \(\hat{\theta}\)
Un estimador \(\hat{\theta}\) es consistente para \(\theta_0\) si:
\[p\lim \hat{\theta}=\theta_0\]
Si un estimador es insesgado no implica que sea consistente
Un estimador insesgado permite variabilidad alrededor de \(\theta_0\) que puede no desaparecer cuando \(N\to \infty\)
Si un estimador es consistente no implica que sea insesgado
Contraejemplo: sumar \(1/N\) a un estimador insesgado y consistente
El nuevo estimador será sesgado pero consistente
Teorema de Slutsky
Sea \(b_N\) un vector de dimensión finita y \(g(\cdot)\) una función real y continua en un vector \(b\), entonces:
\[b_n \xrightarrow{p}b \implies g(b_N)\xrightarrow{p}g(b)\] Por ejemplo, si \(p\lim(b_{1N},b_{2N})=(b_1,b_2)\), entonces \(p\lim(b_{1N} b_{2N})=(b_1 b_2)\)
Leyes de grandes números (LGN)
Las LGN son teoremas de convergencia en probabilidad cuando \(\{b_N\}\) es un promedio muestral, \(b_N\equiv \bar{X}_N\)
Son teoremas para establecer el límite de una secuencia \(\{b_N\}\) en vez de usar fuerza bruta y aplicar la definición
\(X_i\) aquí representa una variable aleatoria, no necesariamente “las \(X\)” en una matriz de datos (podría ser \(X_i=x_iu_i\))
Una ley de grandes números débil: especifica las condiciones sobre los \(X_i\) en \(\bar{X}_N\) para que
\[(\bar{X}_N-E(\bar{X}_N))\xrightarrow{p}0\]
Una LGN débil implica que \(p\lim\bar{X}_N=\lim E(\bar{X}_N)\)
Y si los \(X_i\) tienen una media común, entonces \(p\lim\bar{X}_N=\mu\)
Leyes de grandes números (LGN)
LGN de Khinchine
Si \(\{X_i\}\) son iid y \(E(X_i)\) existe, entonces \((\bar{X}_n-\mu \xrightarrow{p}0)\)
LGN fuertes
Relajan las condiciones sobre \(X_i\) para casos más generales
Ver apéndice en CT
Por ejmpelo, la LGN de Kolmogorov o la de de Markov
En la mayoría de los casos, se usan los TLC a la versión normalizada de \(\bar{X}_N\), es decir, \(\sqrt{N}\bar{X}_N=N^{-1/2}\sum_{i=1}^N X_i\) porque \(V(h(N)\bar{X}_N)=V(\sqrt{N}\bar{X}_N)\) es finita
Teoremas del límite central (TLC)
TLC de Lindeberg-Levy
Sea \(\{X_i\}\) iid con \(E(X_i)=\mu\) y \(V(X_i)=\sigma^2\), entonces
Entonces \(\hat{\beta}_{MCO}\) es consistente para \(\beta\), es decir, \(p\lim\hat{\beta}_{MCO}=\beta\) si \(p\lim N^{-1}X'u=0\)
Si se puede aplicar una LGN al promedio \(N^{-1}X'u=N^{-1}\sum_ix_iu_i\) , una condición necesaria es que \(E(x_iu_i)=0\)
Esta es la condición sobre los errores que enumerábamos en nuestra lista de supuestos en los cursos básicos de econometría
Es la condición clave para la consistencia
Distribución límite
Dada la consistencia del estimador de MCO,la distribución límite de \(\hat{\beta}_{MCO}\) tiene toda su masa en \(\beta\)
Podemos reescalar multiplicando por \(\sqrt{N}\), lo que nos permite obtener una variable aleatoria con varianza distinta de cero y asintóticamente finita:
Sabemos que \(p\lim(N^{-1}X'X)\) existe y es una matriz finita distinta de \(\mathbf{0}\)
Si se puede aplicar un TLC, \(N^{-1/2}X'u\) tendrá una distribución con matriz de covarianzas no singular y finita
Por la regla del límite normal del producto \((N^{-1}X'X)^{-1}N^{-1/2}X'u\) tendrá una distribución límite normal
Distribución del estimador de MCO (Proposición 4.1 en CT)
Supuestos: 1. El proceso generador de datos es \(y=X\beta+u\) 1. Los datos son independientes entre \(i\), \(E(u|X)=0\) y \(E(uu'|X)=\Omega=Diag(\sigma_i^2)\) 1. \(X\) es de rango completo 1. La matriz \(M_{XX}=p\lim N^{-1}X'X=\lim\sum_iE(x_ix_i')\) existe y es finita y no singular 1. El vector \(N^{-1/2}X'u\xrightarrow{d}\mathcal{N}(0,M_{X\Omega X})\), donde \[M_{X\Omega X}=p\lim N^{-1}X'uu'X=\lim N^{-1}\sum_iE(u_i^2x_ix_i')\]
Entonces \(\hat{\beta}_{MCO}\) es consitente para \(\beta\) y la distribución limite de \(\sqrt{N}(\hat{\beta}_{MCO}-\beta)\) es
Pero si \(V(u_i|x_i)=E(u_i^2|x_i)=\sigma_i^2\), es decir, los errores varían con \(i\), White (1980) propone usar como estimador de la varianza a \(\hat{M}_{X\Omega X}=N^{-1}\sum_i \hat{u}_i^2x_ix_i'\), dando lugar a:
En muchas ocasiones, las simulaciones nos serán útiles para mostrar resultados teóricos cuando trabajamos con datos
La idea es crear un proceso generador de datos en donde nosotros conocemos los parámetros poblacionales
En la práctica, regularmente trabajamos con muestras y no conocemos los parámetros poblacionales que dan origen a los datos que observamos
El propósito de las simulaciones Monte Carlo es evaluar el desempeño de los estimadores
Simulaciones Monte Carlo
Pensemos que queremos estimar el parámetro de la media \(\mu\) de una variable con distribución normal usando una muestra de tamaño \(n\): \(y_i=\mathcal{N}(\mu,\sigma^2)\)
Sabemos de nuestras clases de estadística que un estimador es la media muestral \(\bar{y}\)
También sabemos de nuestras clases de estadística que la media muestral tendrá la siguiente distribución:
\[\bar{y}=\mathcal{N}(\mu,\sigma^2/n)\]
Podemos usar simulaciones para mostrar que esto es cierto
Simulaciones en R
Generemos una muestra y calculemos su media
# Semilla para poder generar la misma secuencia set.seed(820)# Obtenemos una muestra de tamaño 100 con media 10 y desviación estándar 2sample <-rnorm(100,10,2)# Veamos 10 de las observacioneshead(sample,10)
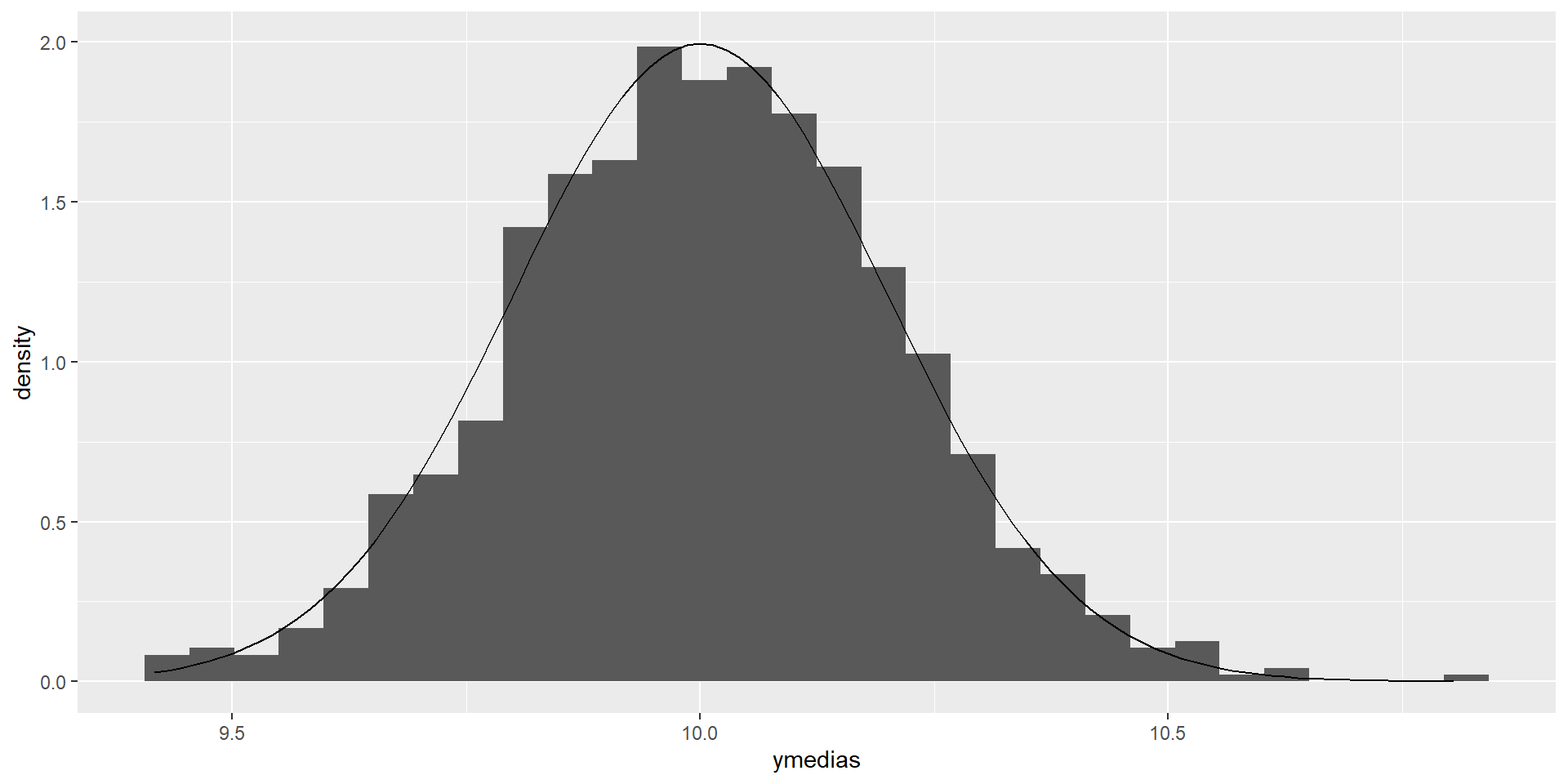
Teóricamente, sabemos que la varianza de la media muestral debería ser \(2^2/100=0.04\)
Podemos repetir el proceso anterior muchas veces
set.seed(820)# Un vector para guardar las medias calculadas. Haremos 1,000 cálculosreps <-1000ymedias <-numeric(reps)# En cada una de las 1000 repeticiones, obtendremos una muestra de tamaño 100for (i in1:reps){ sample<-rnorm(100,10,2) ymedias[i]<-mean(sample)}
Simulaciones en R
Veamos la media y desviación estándar de las medias calculadas:
mean(ymedias)
[1] 10.0084
var(ymedias)
[1] 0.0413458
Simulaciones en R
Podemos hacer un histograma de la distribución de las medias estimadas
Le sobreponemos una curva normal con los parámetros teóricos de la distribución
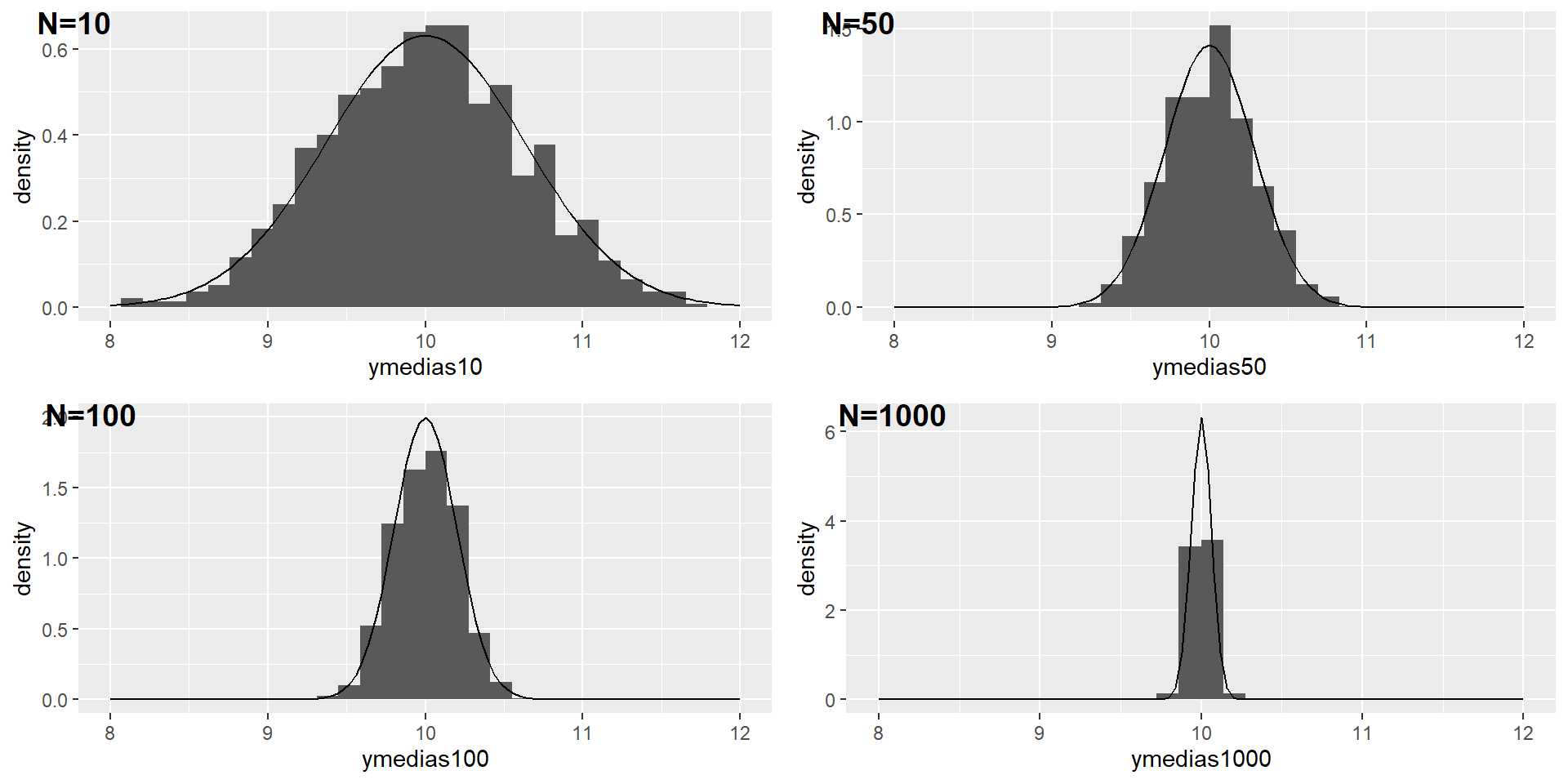
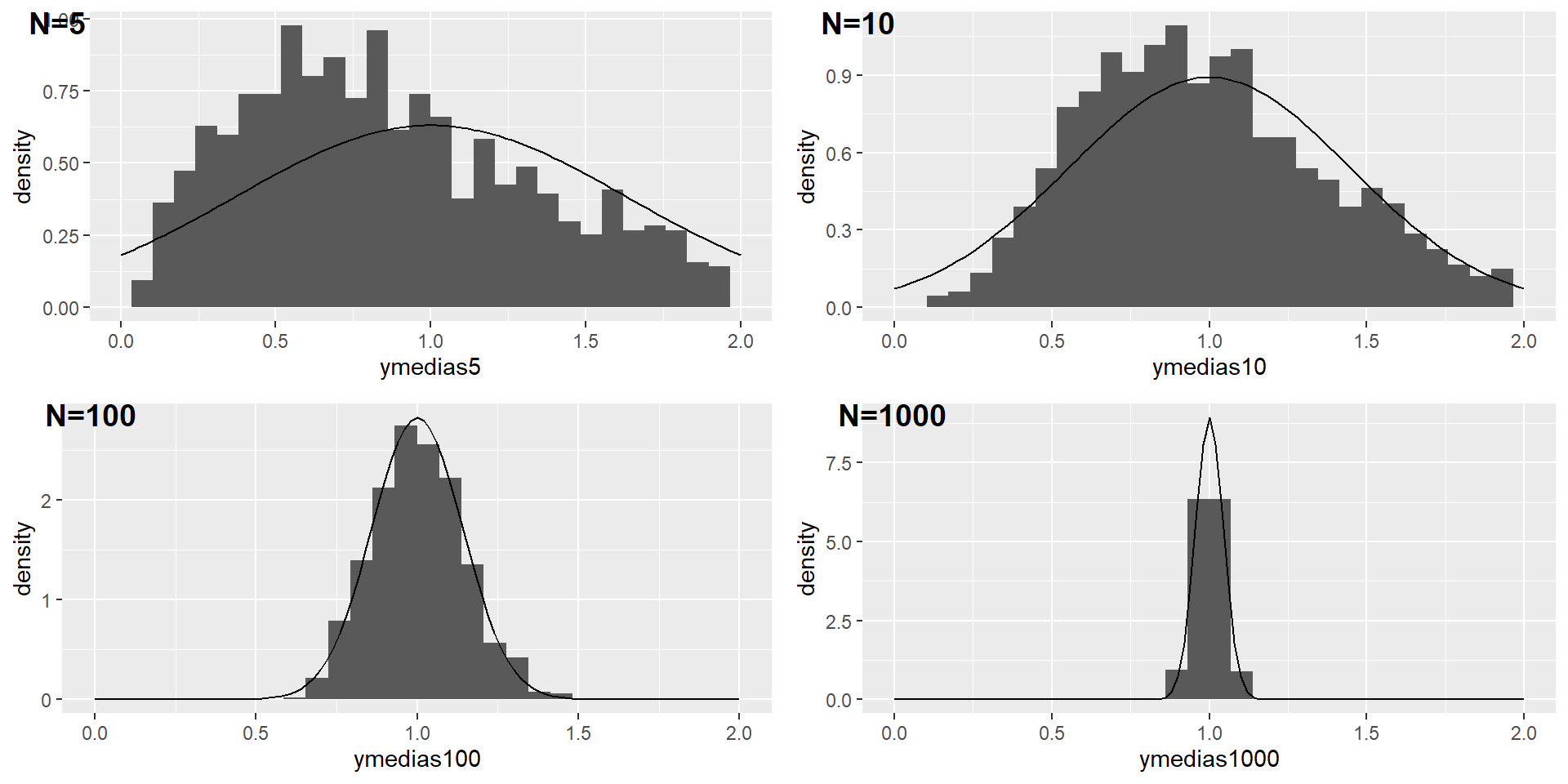
Ahora tomaremos muestras de esta población, repitiendo el procedimiento 1000 veces
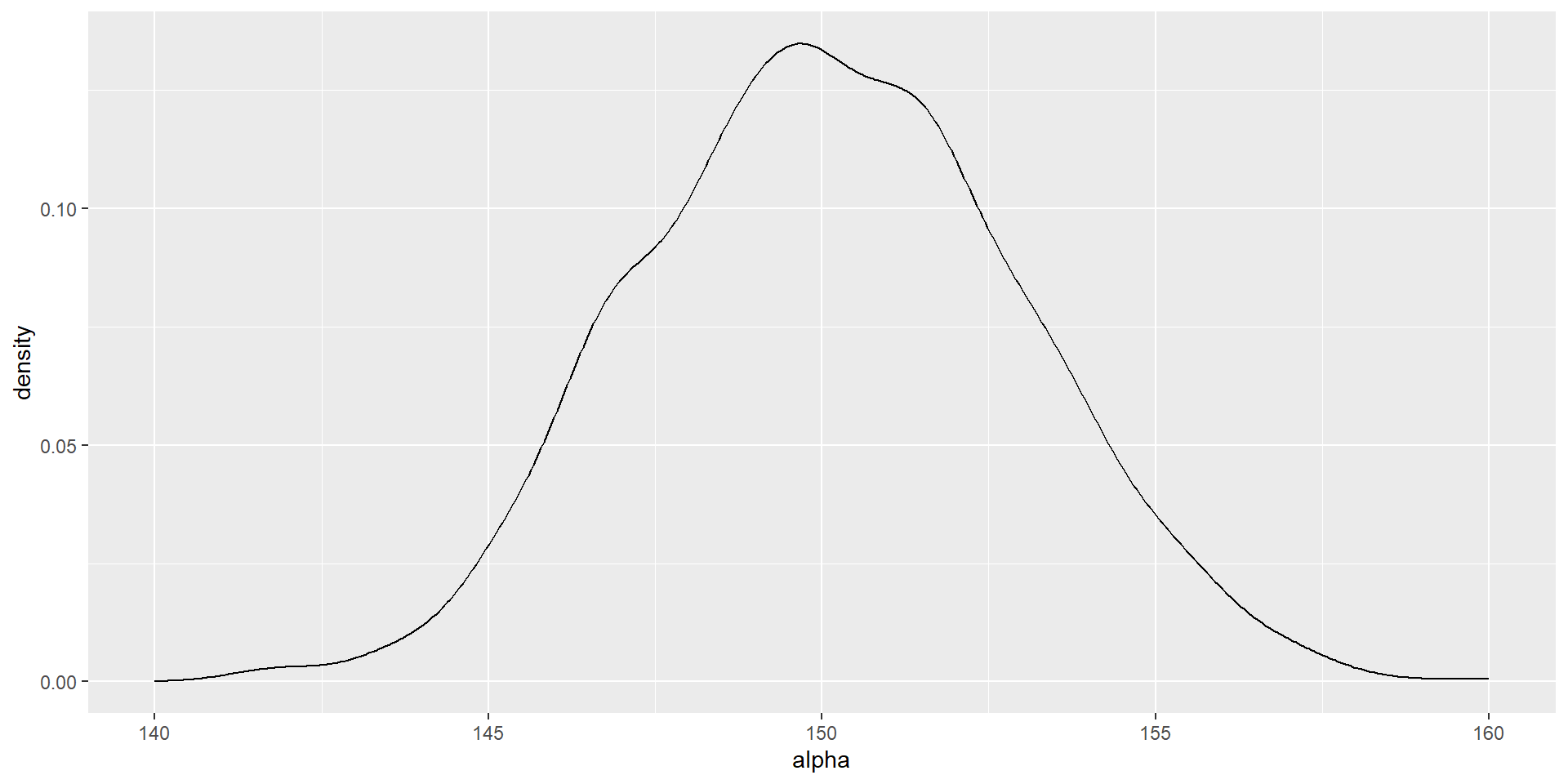
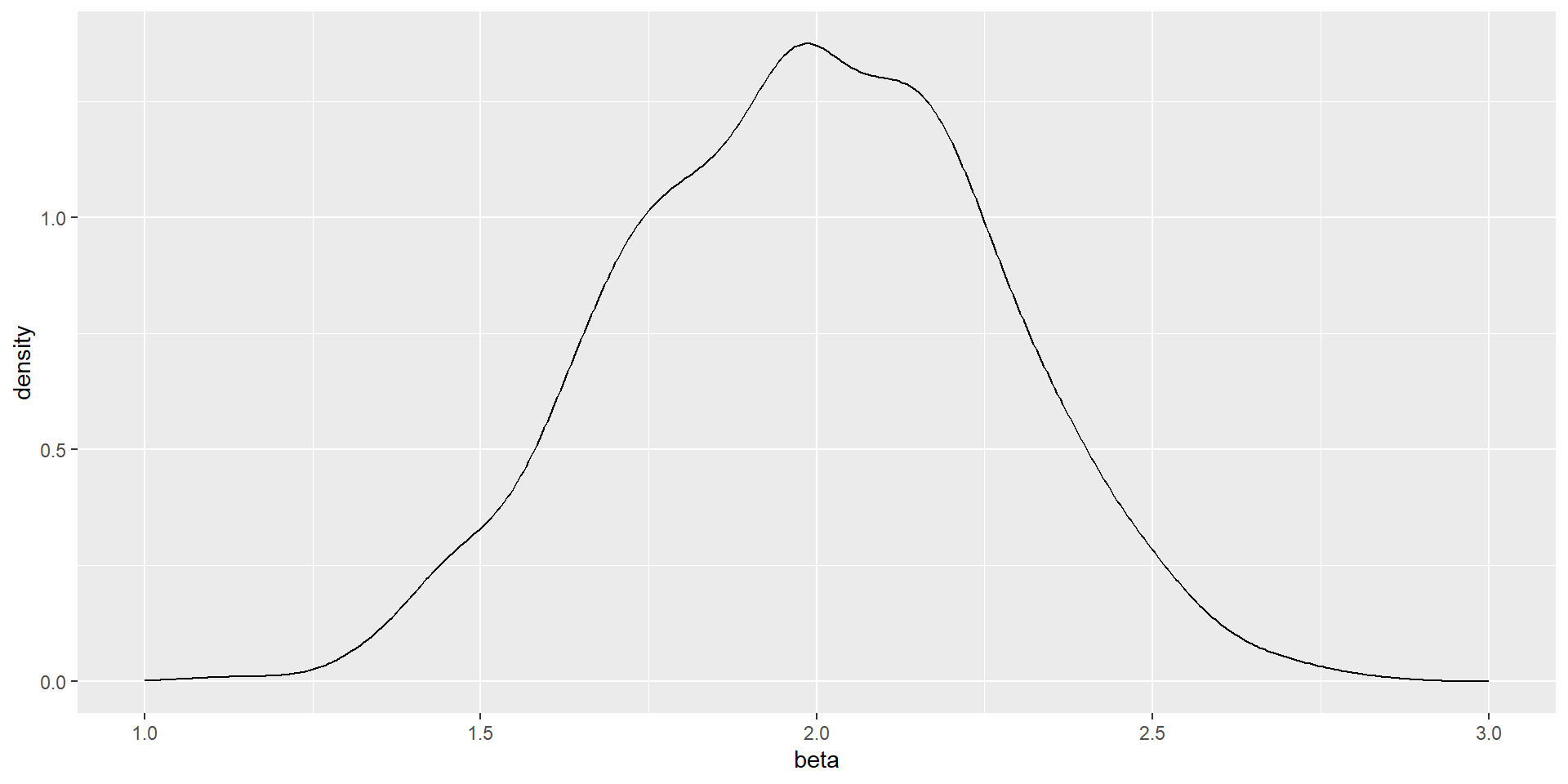
En cada vez, estimaremos la regresión por MCO para obtener \(\hat{\alpha}\) y \(\hat{\beta}\)
Por ejemplo, comencemos con \(n=100\)
#Tomamos muestras de tamaño N y estimamos por MCO#Hacemos este rep veces para cada tamañoreps <-1000#Inicializamos una matriz para guardar resultadosestimadores_mco <-matrix(ncol =2, nrow = reps)#Hacemos reps veces el procedimientofor (i in1:reps){ muestra <- poblacion[sample(1:100000, size=100), ] estimadores_mco[i, ] <-lm(salario ~ educacion, data = muestra)$coefficients}
LGN y TLC en acción
Construyamos la densidad para \(\hat{\alpha}\) y \(\hat{\beta}\) (veremos con detalle qué es la densidad estimada más adelante)
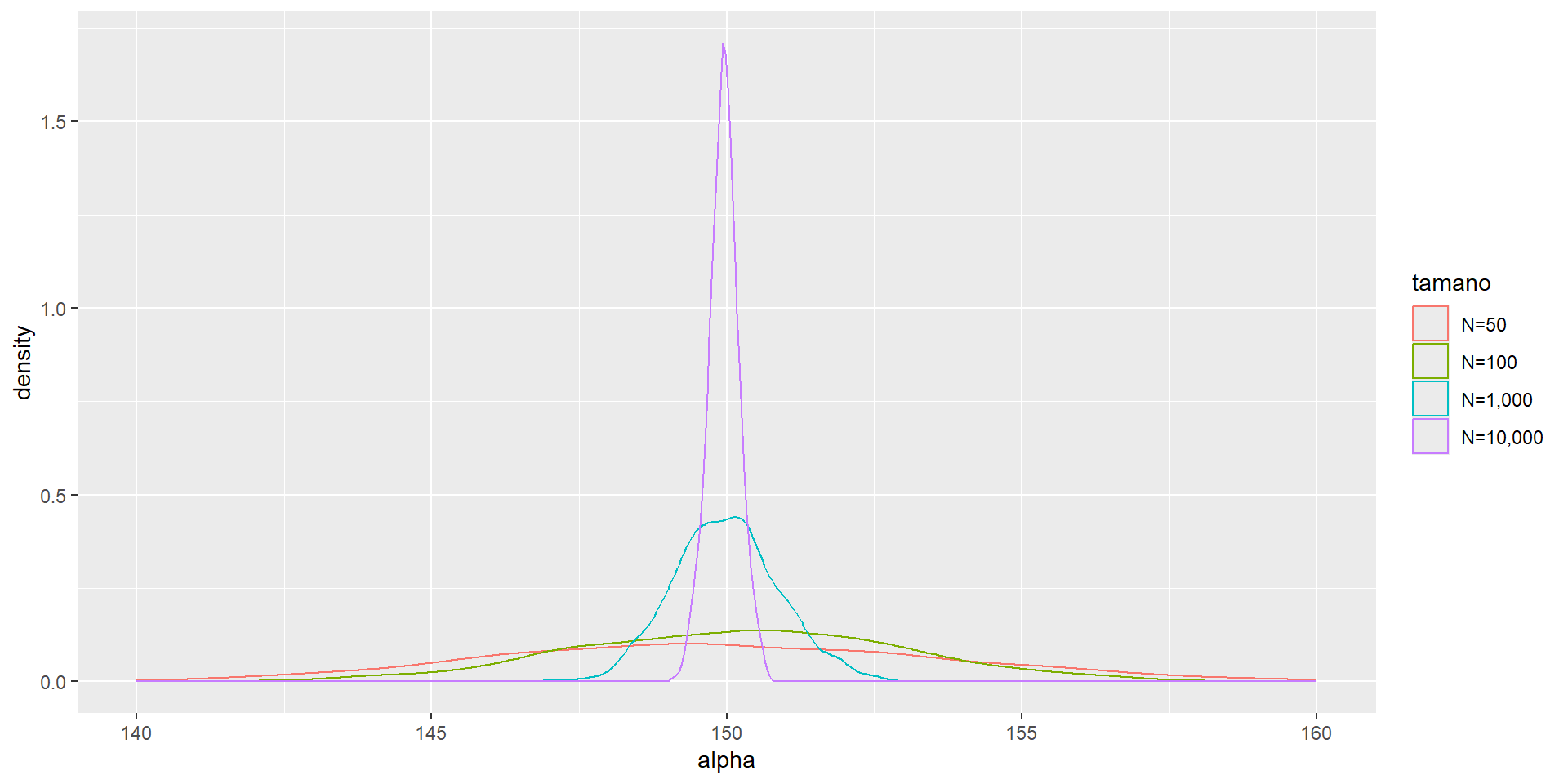
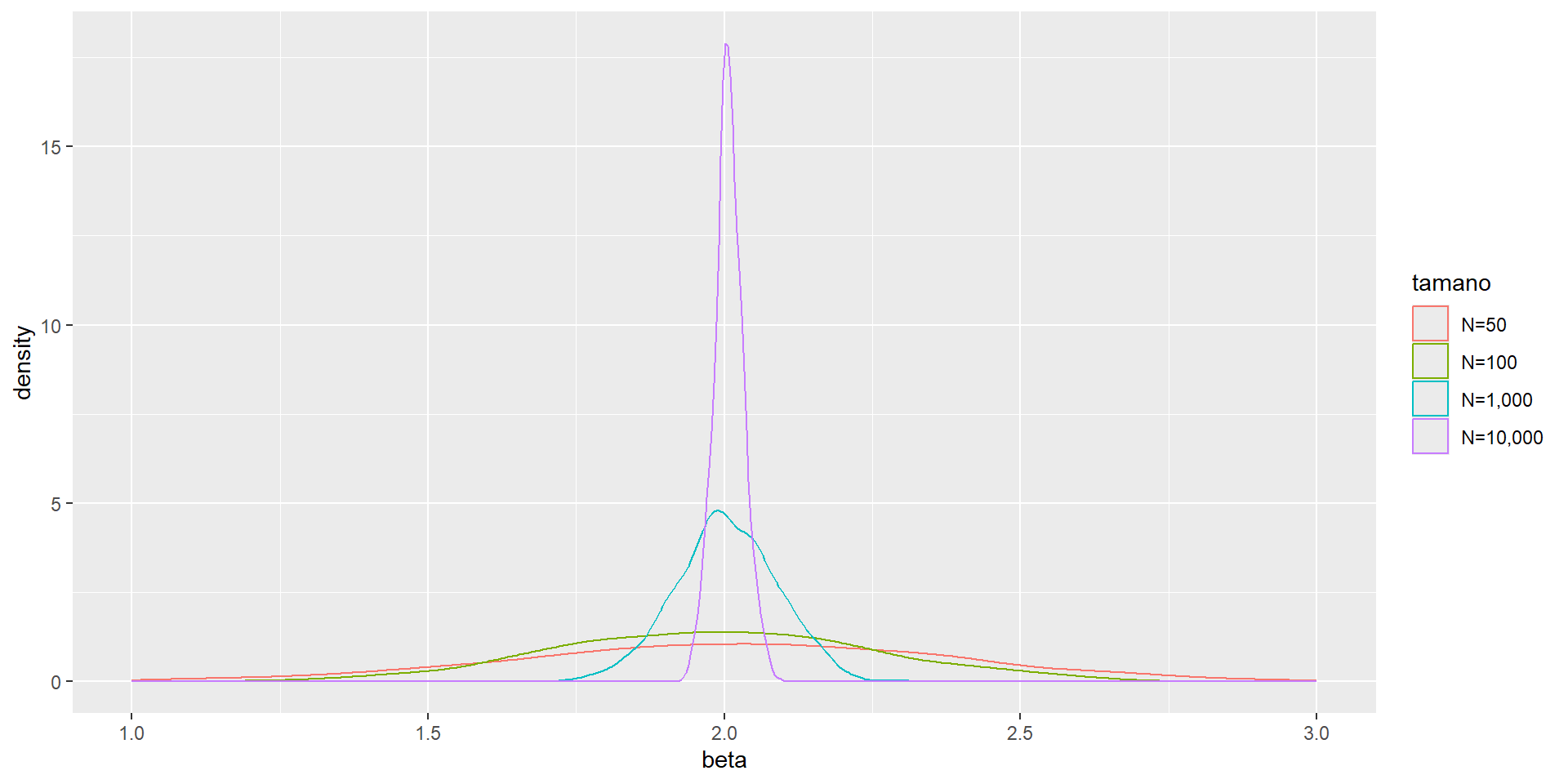
Ahora modificamos el programa que especificaba \(n=100\) para mostrar que \(\hat{\alpha}\) y \(\hat{\beta}\) tienen una masa que se concentra en su media cuando crece el tamaño de la muestra
Voy a hacer dos loops, uno para el tamaño de la muestra y otro para las repeticiones
reps <-1000tamano_muestra <-c(50, 100, 1000, 10000)#Inicializamos una matrices para guardar resultadoscoleccion_estimadores_mco <-matrix(ncol=3,nrow=1)estimadores_mco <-matrix(ncol =3, nrow = reps)
LGN y TLC en acción
Hago la simulación
#Dos loopsfor (j in1:length(tamano_muestra)){for (i in1:reps){ muestra <- poblacion[sample(1:100000, size=tamano_muestra[j]), ] estimadores_mco[i,1:2] <-lm(salario ~ educacion, data = muestra)$coefficients estimadores_mco[,3] <- tamano_muestra[j] }#Vamos apilando los resultados en coleccion_estimadores_mcocoleccion_estimadores_mco <-rbind(coleccion_estimadores_mco, estimadores_mco) estimadores_mco <-matrix(ncol =3, nrow = reps)}
LGN y TLC en acción
Arreglamos el objeto
#Quito la primera fila, que son NAscoleccion_estimadores_mco <- coleccion_estimadores_mco[-1,]coleccion_estimadores_mco <-data.frame(coleccion_estimadores_mco) %>%rename(alpha=X1,beta=X2,tamano=X3)#Aquí veremos la funcionalidad de los factorescoleccion_estimadores_mco <- coleccion_estimadores_mco %>%mutate(tamano=factor(tamano,levels =c(50, 100, 1000, 10000),labels =c("N=50", "N=100", "N=1,000", "N=10,000")))